Backpropagation Through Matrix Multiplication
TL;DR
In this long and technical blog, I explained:
Forward propagation: How inputs flow through the network layer by layer (using matrix operations) to generate predictions.
Computation Graph: How simple scalar examples help visualize backpropagation and build intuition before scaling up.
Backward propagation: How errors flow backward (again with matrix operations) to compute gradients and update weights.
Backpropagation appears quite straightforward when working with scalars or even simple vectors. However, once we step into the world of matrices, things quickly become more complex and difficult to follow. There are extra details and notations that make it less intuitive.
Personally, although I managed to understand this concept while preparing for deep learning exams, I usually lose my intuition a few months later. Reviewing it again requires extra effort to bring everything back together. That's why I decided to write this technical blog post, both as a reminder for myself and as a guide for anyone trying to understand backpropagation in matrix form.
1 - Forward Propagation
When training a deep learning model, the first step is to compute a linear combination of input features. Given an input vector with features and a corresponding weight vector , we calculate a weighted sum and add a bias term to produce a single output :
This is simply the dot product between and with an added bias term:
To visualize this computation, we can represent it in matrix form:
or in image representation:
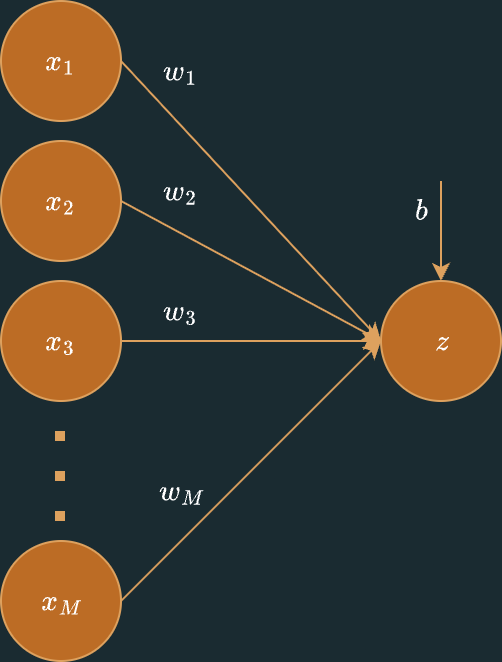
We can simplify our notation by incorporating the bias term directly into the weight vector. This involves adding the bias as the first element of the weight vector and including a constant input :
For notational clarity, we'll denote the bias term as and the constant input as . Under this convention, both vectors have dimension : and . Our equation becomes:
or in matrix form:
or in image representation:

1.1 - Adding Non-Linearity
The linear combination alone is insufficient for learning complex patterns. To add non-linearity, we apply an activation function to the output .
Although often denotes the Sigmoid function, here it represents a general activation function. For this explanation, we'll use the ReLU activation function in hidden layers due to its simplicity, computational efficiency, resistance to vanishing gradients, and widespread popularity:
we can show this with visual representation:

1.2 - Multi-class Classification
In practice, deep learning models often solve multi-class problems where we need to predict one of possible classes. This requires the output to be -dimensional vector, with each dimension representing the score for a particular class. The predicted class corresponds to the entry with the highest activation value.
To generate outputs, we need distinct weight vectors, each of dimension . To achieve this, we need a separate weight vector for each class. Stacking them gives a weight matrix :
or in expanded form:
or in visual form:

Each figure represents the same network, but highlights different output paths from the same inputs, and each path is computed by its own set of output weights.
1.3 - Batch Processing
The computations described so far process only a single input example (batch size = 1). In practice, we process multiple inputs in parallel to improve computational efficiency.
If we process batch size of inputs simultaneously, then our input becomes (note the uppercase since we now have a matrix rather than a vector). To handle outputs while maintaining proper matrix dimensions, we transpose our weight matrix to :
or in matrix form:
When dealing with batches, it can sometimes be hard to picture how forward propagation works. We can visualize the process like this:

Note that in this illustration, the non-linearity (activation function) is not explicitly shown. The final output actually corresponds to the activated values.
1.4 - Multi-layer Networks
The calculations presented so far describe a single layer. Deep learning models stack multiple layers to learn increasingly complex representations. We can denote each layer with a superscript to represent the layer number:
Here represents the number of hidden units in layer . The input to layer activated output from the previous layer . For simplicity, we usually define (the input layer).
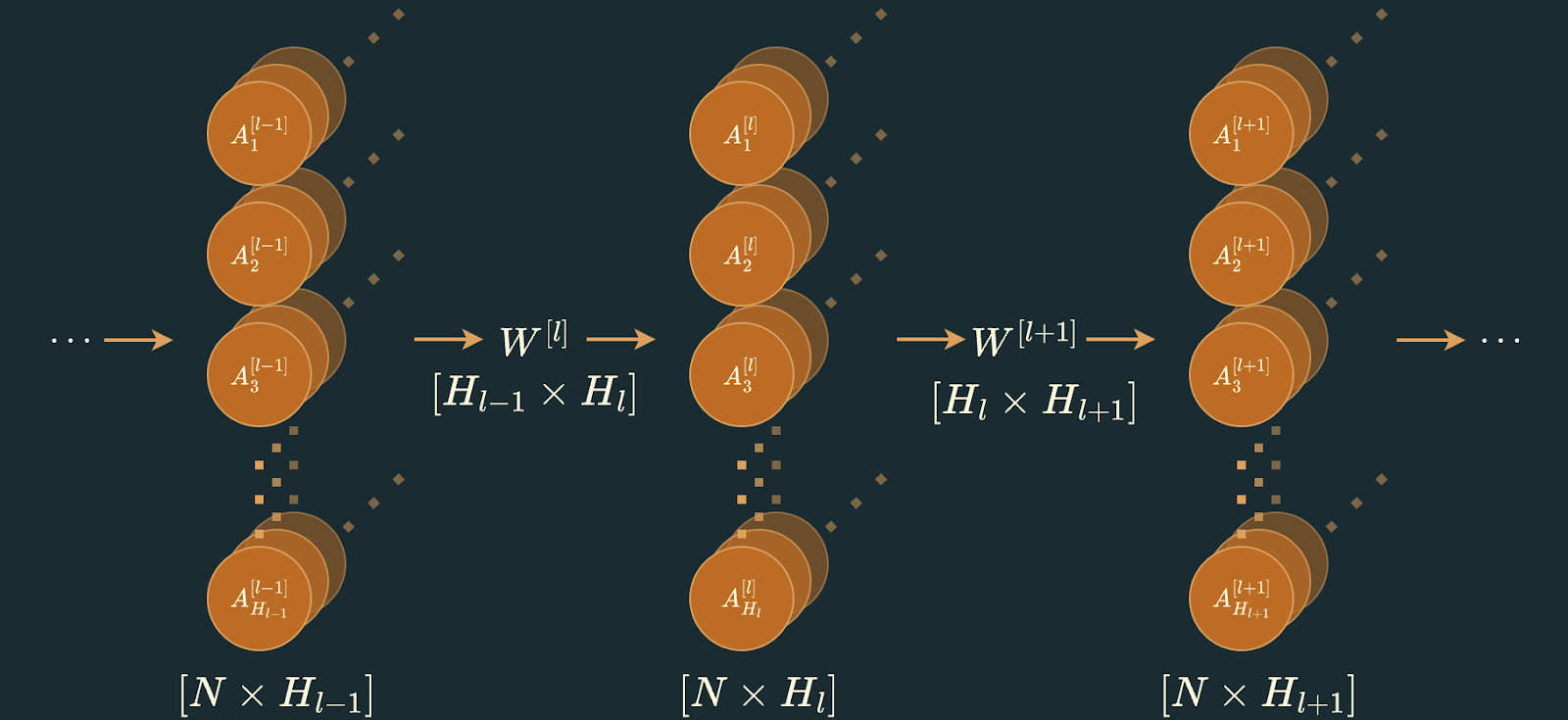
1.5 - Softmax for Classification
For classification problems, we apply the softmax activation function to the final layer's output to convert the raw scores into a probability distribution. The softmax function ensures that all outputs sum to 1, allowing us to interpret them as class probabilities.
The softmax function is applied row-wise (for each input example) across the classes:
Intuitively, for input example , this computes the probability of class by normalizing the exponential of its score by the sum of exponentials across all possible classes.
The matrix representation shows this row-wise operation:
If we denote the last layer as , then the model’s output for inputs and classes can be represented as follows:

1.6 - Cross-Entropy Loss Function
After obtaining the predicted probabilities , we measure the model's performance by comparing these predictions with the ground truth labels using a loss function. The ground truth is represented as one-hot encoded vectors, where each input example has exactly one correct class. For multi-class classification, we typically use Cross-Entropy (CE) loss:
This formula computes the element-wise product between the true labels and the logarithm of predicted probabilities then averages across all examples to produce a single scalar loss value.
We can express this using matrix operations with the element-wise (Hadamard) product :
Expanding this matrix operation:
We can simplify this by recognizing that multiplying by vectors of ones simply sums all elements in the matrix. Therefore:
We can show this summation with following image (excluding scaling factor ):

Although this is a general representation, we denote the output cross-entropy loss as . Since the ground truth is one-hot vector, it is 1 for true class and 0 for others in each input. Therefore, the assumption in this case can be:
This completes our mathematical framework for forward propagation in deep learning models, from single predictions to batch processing with multi-class classification and loss computation.
2 - A Simple Computation Graph
Before diving lots of matrix gradient calculation, I would like to show a computation graph for forward and backward propagation so we can see the cases we need to be careful when we compute gradients. In this case, I want to only show scalar calculations first instead of thinking about matrices so we can adapt this into matrix backpropagation.
where and represents arbitrary layer and last layer , respectively. is activation function (ReLU in this case). In this representation, everything is scalar except because the output must be multi-class for softmax so I just played in the last layer to show a meaningful example.
We can visualize the computation graph of this network as follows:

2.1 - Chain Rule
Backpropagation relies on the chain rule of calculus to compute gradients efficiently. For a composite function , the chain rule states:
In neural networks, we apply this principle to decompose the loss gradient into a product of simpler derivatives based on any parameter.
2.2 - Scalar Backward Propagation
After computing loss, we can start computing gradients with respect to it. Since there are classes, we need to calculate derivative of each prediction :
We can visualize this gradient flow like this:

Since the predicted output is computed using in both the numerator and the denominator
the derivative depends not only on the numerator but also on the denominator:
It might be easier to understand when you see visual representation:

Since we already know , the gradient expression simplifies to:
The most confusing part begins here, because we now need to carefully compute the local gradient . To do this, we apply the quotient rule:
For this derivative, there are two distinct cases to consider:
Case 1:
- The derivative of numerator:
- The derivative of the denominator is:
- Substituting these into the quotient rule:
- Factorizing into:
- Shortly, this is equivalent to:
Case 2:
The derivative of the numerator is zero, because does not depend on .
The derivative of the denominator is:
- Thus, we have:
- Simplifying:
- Shortly, this is equivalent to:
Finally, we can summarize these two cases as
In literature, it is pretty common to use the following form:
where is 1 if , 0 otherwise. When we combine the gradient of cross-entropy and local gradient, we have:
where cancels each other:
Since ground truth value is one-hot vector (1 for true class and 0 for others), equation simplifies to:
This compact form is what makes softmax combined with cross-entropy loss so useful. Instead of dealing with complicated fractions, we can directly use this result to propagate gradients to the next layers.
From this point, gradient calculations across layers will start to follow a recurring pattern. Each layer essentially repeats the same process: we compute gradients with respect to its inputs and its weights.
For the layer output , we have two key variables to differentiate with respect to:
The weights : their gradients are crucial because they are the trainable parameters we want to optimize during learning.
The activations : while not parameters themselves, their gradients are equally important since they ensure the flow of gradients backward through the network, enabling earlier layers to update as well.
Thus, even though only the weight gradients directly influence optimization, the activation gradients play a important role in keeping backpropagation alive throughout the entire network:

- If we calculate derivatives with respect to weights :
- If we calculate derivatives with respect to weights :
Lastly, we need to calculate the derivative of with respect to in (assuming ReLU()):
where outputs 1 if , 0 otherwise as a indicator function.
Therefore, we can summarize backpropagation for scalar values with following pattern:
3 - Backward Propagation
After computing the loss through forward propagation, we need to update the model's weights to minimize this loss. Backpropagation is the algorithm that computes the gradients of the loss function with respect to each parameter in the network. We'll derive these gradients step by step, working backwards from the loss to the input layer.
3.1 - Gradient of Cross-Entropy with Softmax
Starting with loss function, we calculate relative gradients and go back step by step to calculate further gradients. Since the model has predictions with Softmax activation and the loss is calculated with cross-entropy, the combination of these methods has a nice property which simplifies the gradient:
or in matrix representation:
or in visual representation:

3.2 - Gradient of Arbitrary Layer
At this stage, we can begin calculating the gradients of the weights in the corresponding layer. Since the forward propagation is computed as
there are two possible local gradients we might consider:
You may wonder why we would need the gradient with respect to since our goal is to update the weight matrix . The reason is that the derivative with respect to becomes necessary for updating the weights of the previous layer, because
When we want to calculate the gradients of weight matrix with respect to the loss function , we use chain rule as follows:
The local gradient gives us:
Since there are values in weight matrix , we need to find each individual gradient so the shape of should be . However, the dimensions of matrices does not match when we try to calculate matrix multiplication:
If we take transpose of and place it to the left side of upstream gradient, we have the correct dimension matching:
At first glance, this transformation may seem arbitrary. Why do we transpose? How can we be sure this result is correct? To clarify, let’s check the matrix representation:
If we look closely only one gradient calculation, :
Since single value of weight matrix is fixed for each input value, the gradient of this weight is just summation of all N input derivatives:
In the image below, you can see the visualization of this calculation for 4 weights in the network:

At the same time, we need to calculate the derivative of , , so upstream gradients can flow to previous layer and the gradient of weight matrix can be calculated in that layer:
The local gradient is:
Once again, the dimensions of matrices do not match:
We can transpose the weight matrix to align matrices:
We can see the reasoning more easily if we check matrix representation again:
By focusing on only first value, , the gradient of depends on the values that it affected during forward propagation (the same logic as ) :
Now we want to compute the gradient . Recall that is obtained by applying an activation function to :
In our examples, we use the ReLU activation function. Its derivative with respect to each element is given by:
For inputs, we must compute a gradient for each element, producing a matrix of 0s and 1s. The derivative of ReLU applied element-wise can be written as the indicator (mask) of positive entries:
where is the element-wise indicator function (1 when the condition is true, 0 otherwise). In matrix form:
Because the derivative is applied element-wise, the upstream gradient is combined with this mask element-wise, not by matrix multiplication:
or
3.3 - Repetition
At this point, we completed the backpropagation using the matrix multiplication step. From here on, the process is essentially a repetition: each layer applies the same logic and propagates the gradients backwards through the weights (also biases implicitly) and activations.
The only real exception was the output layer, where we combined the softmax function with cross-entropy loss. This required a more detailed derivation, but the model is consistent for all hidden layers and is repeated across the entire network. You can see the pattern as follows:
I know it looks ugly but if you pay some attention, you will see the pattern for gradient calculation. There are just some rules that you need to follow for each block.
For comments, please send me an email.